论文推荐 | 如何通过2D图像或视频,推出三维模型?
雷锋网按:本文为雷锋字幕组编译的论文解读短视频,原标题Learning Category-Specific Mesh Reconstruction from Image Collections,作者为Angjoo Kanazawa。
翻译 | 龙珂宇 字幕 | 凡江 整理 | 李逸帆 吴璇
本篇介绍的《从图像集合中学习特定类别的网格重建》是Angjoo Kanazawa最新论文的预印本。
Angjoo Kanazawa,加州大学伯克利分校BAIR(Berkeley AI Research)的博士后。她的论文《狮子、老虎、熊:从图像中捕捉非刚性的3D立体形状》、《SfSNet :“在自然情况下”学习脸部形状、反射比、照明度》都被收录在CVPR 2018。
一直以来,Angjoo的研究重点都是包括人类在内的动物单视图三维重建。比如,我们如何能够通过观察2D图像或视频,来推出三维模型?
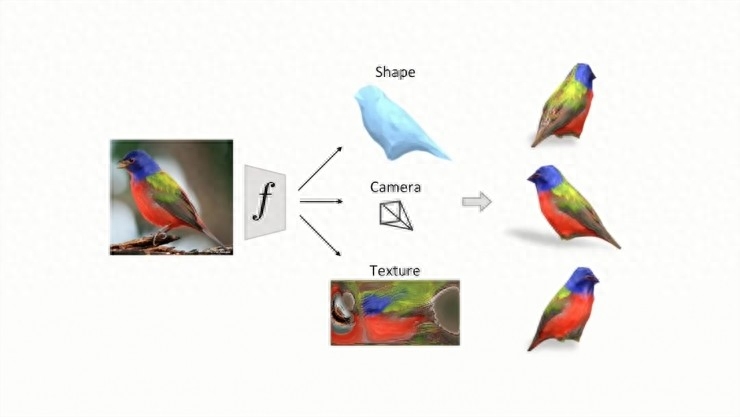
如图所示,虽然这是一个二维的平面图片,但我们可以大致推断出它的3D轮廓,甚至可以想像出从另一个角度看它是什么样的。

在这次的工作中,我们的目标就是建造一个类似的计算模型。从单张平面图片推断出3D模型的说法并不太准确,它仅在我们具备一只鸟长什么样的基础知识的情况下才可能实现。原来的办法主要通过3D基准形状来获得这种基础知识,要么是绘制的合成图要么是物体的扫描图。但不幸的是,这种扫描方法在实际上,很难用到活体对象上面,因为我们很难让他们配合我们的扫描,所以我们试图采用一种更自然的监督方法——就是大量的标注图片集合。

假设我们对于一个物体类别有大量的图片集,但对于每一个个体都只包括一个角度,每一张图片都被添加了一组语义描述和正确的分割蒙版。从这个图片合集和蒙版上的标注,我们学习到一个预测器F,在给定一张新的未标注图片时,F可以推断它的3D形状并用网格表示,可以推断其观测视角,以及其网格结构。通过这些推断和预测,我们就得到了关于这个物体3D形状的一个表示。从任何一个视角渲染这个模型,都可以把它直观地可视化。
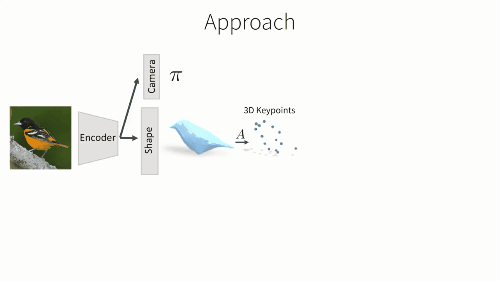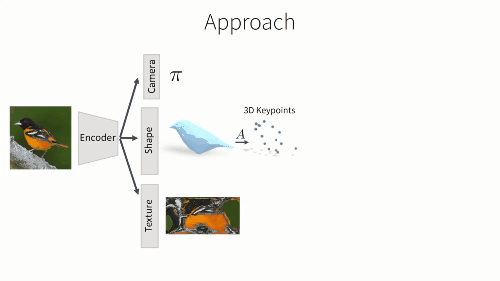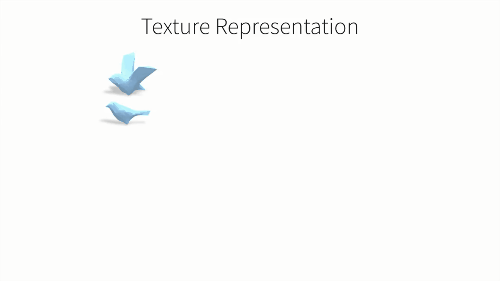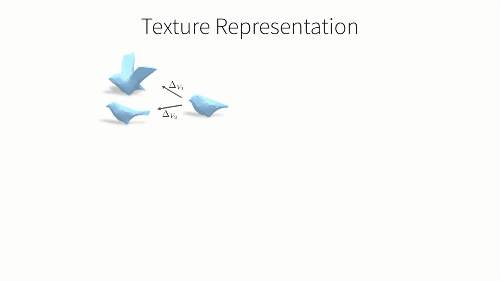
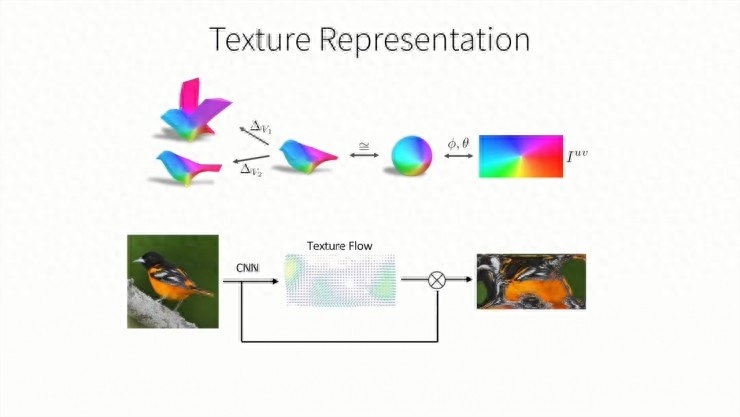
F是一个CNN神经网络,包括一个图像解码器和三个预测模块。首先我们预测相机的观测视角,其参数由弱透视投影变化决定。第二个输出是物体的3D形状,它是一个和类别有关的形变模型。我们将学习到的该类级别模型和当前输入的预测形变相结合,然后获得输出的3D形状。这样一个类级别模型的好处在于——我们可以学习到如何关联语义标注和网格的格点,同时也能从预测形状中,获得3D关键点的位置。最后,我们还可以通过一张正则形态空间中的RGB图像表达,预测出它的纹理结构。
那么该如何,从这张二维图片中看出,我们对纹理结构的预测呢?我们注意到,一个类别中的不同形状其实只是平均形状的一个形变,而其平均形状可以被视为一个球体,其纹理可以用一张UV纹理图片来表示,就像把一个球体展开到二维平面上。UV图也可以被映射到球体上,然后被变化到平均形状或者任何预测出的形状上。所以,为了预测形状的纹理,我们只需要预测UV图中的颜色,所以我们通过一个CNN结构来实现它。我们将输入图片编码后传入CNN,这里,我们并不是直接预测,纹理图片的像素信息,而是预测他的纹理流。
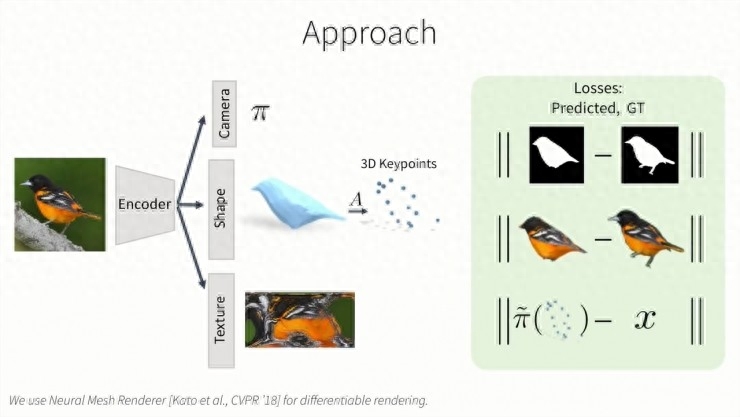
在获得预测信息之后,我们用同样的办法表示出我们的目标物体,然后使得预测值更接近真实值。我们最小化预测结果和真实结果的渲染蒙版,渲染图片和投影关键点之间距离。我们使用神经网格渲染器,所以。所有损失函数都是可微的。同时我们也在模型中包含了一些先验信息,如对称性,表面的光滑性等等。
现在我们在测试集上向大家展示一些训练结果,给定一张输入图片,我们可以推断其在结构中的形状,这里展示了不同视角下的结果。我们的模型也可以捕捉到不同的形状,比如说翅膀,和不同的尾部。我们也可以使用我们的结果,将一只鸟的纹理变化到另外一只鸟。比如说,给定这两只鸟的图片,我们首先重建它们的结构和纹理。因为纹理图是在正则形态空间中表示的,我们可以简单地交换它们的纹理图。然后把第二只鸟的纹理变化到第一只鸟身上,反之同理,即使在鸟的形状不同的时候,我们也可以进行纹理变化的操作。比如说这里我们向大家展示一些不同测试数据上的重建结果,大家可以看到它们的360°图片。

雷锋网雷锋网
视频原址 https://www.youtube.com/watch?v=cYHQKtBLI3Q
论文原址 https://arxiv.org/pdf/1803.07549.pdf
[注:本文部分图片来自互联网!未经授权,不得转载!每天跟着我们读更多的书]
互推传媒文章转载自第三方或本站原创生产,如需转载,请联系版权方授权,如有内容如侵犯了你的权益,请联系我们进行删除!
如若转载,请注明出处:http://www.hfwlcm.com/info/300758.html
相关文章
-

大家好,我是CC,马上就要跨年了,先祝大家新的一年心想事成,身体健康。TOI的益智玩具已经不是我第一次购买了,从拼图到桌游,优秀的做工和材质、有创意的构思都是在低幼直至学
-

近日,全国各大高校纷纷晒出给2020级新生的录取通知书。一时间,各大高校纷纷展开花式battle。北京大学的“大学堂”牌匾、清华大学的3D立体校门、北京航空航天大学的剪纸镂空飞机
-
立体的纸花球,看起来折法很复杂其实只需要准备一张小纸折出一个小小的立体形状再用其它不同颜色的小纸继续折几十个同一形状的小组件最后再拼插在一起就有一个超立体的纸花球
-

三维模型3DTile格式轻量化压缩模型变形浅析在对三维模型进行轻量化压缩处理的过程中,常常会出现模型变形的现象。这种变形现象多数源于模型压缩过程中信息丢失或误差累积等因素
-
很多时候,我们在做Simulation分析,目的是为了看我们的产品是否能够承受住载荷的作用而不损坏,产品在载荷作用下,会出现变形,这个变形很多时候我们需要把它记录并生产出(或者
-

最近在乐队的夏天重新认识了张亚东。张亚东从来不缺少热议,音乐才华&娱乐圈情人的这些标签就足够各种正刊/小道八卦津津乐道了。我不懂音乐不了解音乐圈,对他的所谓印象只能从
-

3月1日,周传雄 “今宵酒醒何处”世界巡回演唱会发布会在京举行。文/侯艳 (图片署名: 东方IC) 作为歌坛的“情歌教父”,周传雄曾为自己和他人创作过许多耳熟能详的经典
-
文丨蒋思静在成都出土的永陵“二十四伎乐”石刻,为我们留下唐代宫廷燕乐的缩影,让我们能够依稀一窥得那盛世歌舞。无数音乐家、文学家,在历史中不停追索,让我们得以在今天

